
摸索腾跃式思维链:DeepSeek发明力垫底,Qwen系列
发布时间:2025-03-02 08:36
在年夜言语模子 (LLM) 的研讨中,与以 Chain-of-Thought 为代表的逻辑头脑才能比拟,LLM 中等同主要的 Leap-of-Thought 才能,也称为发明力,现在的探讨跟剖析依然较少。这可能会重大妨碍 LLM 在发明力上的开展。形成这种困局的一个重要起因是,面临「发明力」,咱们很难构建一个适合且主动化的评价流程。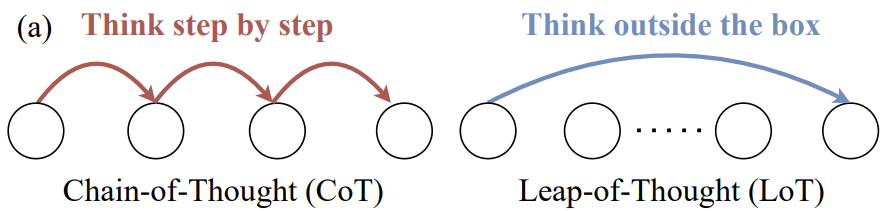 从前年夜少数发明力测评在摸索 LLM 的 Leap-of-Thought 才能的时间,依然遵守一般年夜模子测评中的抉择、排序等评价范例。只管这种评价方法对逻辑头脑才能的考核十分无效,然而在对发明力的评价中则不太公道。如下图所示,假如请求浏览所给图跟图中笔墨,并为图中「?」局部填入一句话,使得团体富有发明力且风趣。假如这个义务是一个抉择题型的义务,并供给了「A. 能够帮助扶一下我吗?」跟「能够帮我解开手铐吗?」,LLM 可能会在无需任何发明力的情形下抉择 B,由于 A 选项很惯例,而 B 选项很特殊。
从前年夜少数发明力测评在摸索 LLM 的 Leap-of-Thought 才能的时间,依然遵守一般年夜模子测评中的抉择、排序等评价范例。只管这种评价方法对逻辑头脑才能的考核十分无效,然而在对发明力的评价中则不太公道。如下图所示,假如请求浏览所给图跟图中笔墨,并为图中「?」局部填入一句话,使得团体富有发明力且风趣。假如这个义务是一个抉择题型的义务,并供给了「A. 能够帮助扶一下我吗?」跟「能够帮我解开手铐吗?」,LLM 可能会在无需任何发明力的情形下抉择 B,由于 A 选项很惯例,而 B 选项很特殊。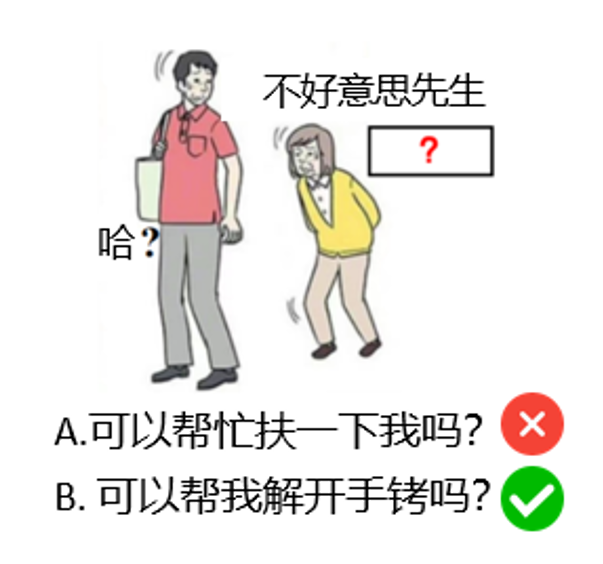 评价 LLM 的发明力应当是「考核其天生翻新内容的才能」,而不是「考核它能否能断定翻新的内容」。在以后的研讨范式中,经由过程人类评价或许 LLM-as-a-judge 的方法合乎这一请求。但是,只管人类评价的正确率最高且合乎人类个别代价不雅,然而这种方法弗成连续且本钱十分高。而 LLM-as-a-judge365bet亚洲体育 这种大抵经由过程 zero-shot 或许 fine-tuning 一个 LLM 来对目的停止评分的方法,其在发明力义务上的评价才能现在依然处于低级阶段,并且不是很稳固。面临这些艰苦,来自中年夜、哈佛、鹏城、新加坡治理年夜学的研讨者另辟门路,经由过程研讨 LLM 发生人类高品质翻新内容所须要的价值 (也能够看作是 LLM 发生内容与人类程度翻新内容的间隔),树立一个多轮交互的可托且主动化发明力评价范式 LoTbench。研讨结果登上了 IEEE TPAMI。
评价 LLM 的发明力应当是「考核其天生翻新内容的才能」,而不是「考核它能否能断定翻新的内容」。在以后的研讨范式中,经由过程人类评价或许 LLM-as-a-judge 的方法合乎这一请求。但是,只管人类评价的正确率最高且合乎人类个别代价不雅,然而这种方法弗成连续且本钱十分高。而 LLM-as-a-judge365bet亚洲体育 这种大抵经由过程 zero-shot 或许 fine-tuning 一个 LLM 来对目的停止评分的方法,其在发明力义务上的评价才能现在依然处于低级阶段,并且不是很稳固。面临这些艰苦,来自中年夜、哈佛、鹏城、新加坡治理年夜学的研讨者另辟门路,经由过程研讨 LLM 发生人类高品质翻新内容所须要的价值 (也能够看作是 LLM 发生内容与人类程度翻新内容的间隔),树立一个多轮交互的可托且主动化发明力评价范式 LoTbench。研讨结果登上了 IEEE TPAMI。 论文标题:A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models论文链接:https://arxiv.org/abs/2501.15147名目主页:https://lotbench.github.io义务场景本论文是 CVPR 24 中「梗王」年夜模子(Let s Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with 188体育线上平台Creative Humor Generation)的期刊扩大,其斟酌的发明力基本义务是如图 2 所示的,看图并直接天生补全笔墨中的空白处,使得图文团体显得翻新且风趣。这类义务是日本传统游戏「年夜喜利」游戏的一种,在中文互联网社区也被称为日式冷吐槽。它存在如下一些特色:1.这类日式冷吐槽游戏请求看图并补全存在创意且风趣的笔墨,对发明力请求很高,是典范是发明力成绩;2.这类日式冷吐槽游戏完善合乎以后多模态年夜模子的输入输特别式,即输入时图文沙巴体育官方平台,输出仅为笔墨,并且是年夜模子最善于的笔墨补全义务;3.这类日式冷吐槽游戏因为在互联网上热度十分高,有大批高品质人类标注数据跟带有 ranking 信息的点评数据,对构建数据集很有辅助。综上所述,这类日式冷吐槽游戏是少有的合适多模态 LLM 停止发明力测评的幻想平台。义务内容
论文标题:A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models论文链接:https://arxiv.org/abs/2501.15147名目主页:https://lotbench.github.io义务场景本论文是 CVPR 24 中「梗王」年夜模子(Let s Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with 188体育线上平台Creative Humor Generation)的期刊扩大,其斟酌的发明力基本义务是如图 2 所示的,看图并直接天生补全笔墨中的空白处,使得图文团体显得翻新且风趣。这类义务是日本传统游戏「年夜喜利」游戏的一种,在中文互联网社区也被称为日式冷吐槽。它存在如下一些特色:1.这类日式冷吐槽游戏请求看图并补全存在创意且风趣的笔墨,对发明力请求很高,是典范是发明力成绩;2.这类日式冷吐槽游戏完善合乎以后多模态年夜模子的输入输特别式,即输入时图文沙巴体育官方平台,输出仅为笔墨,并且是年夜模子最善于的笔墨补全义务;3.这类日式冷吐槽游戏因为在互联网上热度十分高,有大批高品质人类标注数据跟带有 ranking 信息的点评数据,对构建数据集很有辅助。综上所述,这类日式冷吐槽游戏是少有的合适多模态 LLM 停止发明力测评的幻想平台。义务内容
从前年夜少数发明力测评在摸索 LLM 的 Leap-of-Thought 才能的时间,依然遵守一般年夜模子测评中的抉择、排序等评价范例。只管这种评价方法对逻辑头脑才能的考核十分无效,然而在对发明力的评价中则不太公道。如下图所示,假如请求浏览所给图跟图中笔墨,并为图中「?」局部填入一句话,使得团体富有发明力且风趣。假如这个义务是一个抉择题型的义务,并供给了「A. 能够帮助扶一下我吗?」跟「能够帮我解开手铐吗?」,LLM 可能会在无需任何发明力的情形下抉择 B,由于 A 选项很惯例,而 B 选项很特殊。评价 LLM 的发明力应当是「考核其天生翻新内容的才能」,而不是「考核它能否能断定翻新的内容」。在以后的研讨范式中,经由过程人类评价或许 LLM-as-a-judge 的方法合乎这一请求。但是,只管人类评价的正确率最高且合乎人类个别代价不雅,然而这种方法弗成连续且本钱十分高。而 LLM-as-a-judge365bet亚洲体育 这种大抵经由过程 zero-shot 或许 fine-tuning 一个 LLM 来对目的停止评分的方法,其在发明力义务上的评价才能现在依然处于低级阶段,并且不是很稳固。面临这些艰苦,来自中年夜、哈佛、鹏城、新加坡治理年夜学的研讨者另辟门路,经由过程研讨 LLM 发生人类高品质翻新内容所须要的价值 (也能够看作是 LLM 发生内容与人类程度翻新内容的间隔),树立一个多轮交互的可托且主动化发明力评价范式 LoTbench。研讨结果登上了 IEEE TPAMI。论文标题:A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models论文链接:https://arxiv.org/abs/2501.15147名目主页:https://lotbench.github.io义务场景本论文是 CVPR 24 中「梗王」年夜模子(Let s Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with 188体育线上平台Creative Humor Generation)的期刊扩大,其斟酌的发明力基本义务是如图 2 所示的,看图并直接天生补全笔墨中的空白处,使得图文团体显得翻新且风趣。这类义务是日本传统游戏「年夜喜利」游戏的一种,在中文互联网社区也被称为日式冷吐槽。它存在如下一些特色:1.这类日式冷吐槽游戏请求看图并补全存在创意且风趣的笔墨,对发明力请求很高,是典范是发明力成绩;2.这类日式冷吐槽游戏完善合乎以后多模态年夜模子的输入输特别式,即输入时图文沙巴体育官方平台,输出仅为笔墨,并且是年夜模子最善于的笔墨补全义务;3.这类日式冷吐槽游戏因为在互联网上热度十分高,有大批高品质人类标注数据跟带有 ranking 信息的点评数据,对构建数据集很有辅助。综上所述,这类日式冷吐槽游戏是少有的合适多模态 LLM 停止发明力测评的幻想平台。义务内容 下一篇:没有了